Docker Swarm Overview
I dette post vil jeg beskrive Docker Swarm, dets anvendelse og fordelene ved at benytte denne teknologi.
Swarm overview
Swarm mode benyttes til orkestrering af en cluster af Docker Engines, altså flere hosts der kører Docker som tilsammen udgør et netværk af kommunikerende containers. I en swarm indgår to typer af hosts: worker og manager. En host, eller node, kan være både manager og worker. Managers rolle er, at holde styr på sværmens ønskede tilstand, herunder hvor mange containers der skal køre af hver service, hvilke nodes de skal køre på, hvordan services opdateres og meget mere. Workers skal blot køre containers. Diagrammet nedenfor giver et overblik:
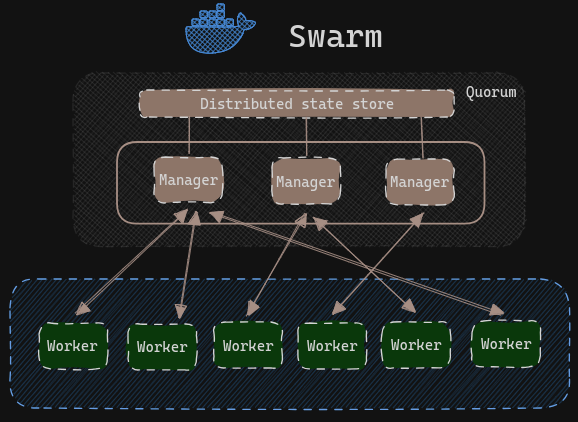
Quorum
En af ens managers er det man kalder leader. Det er denne manager, som er ansvarlig for, at schedule nye tasks (containers), til worker nodes, når en container af en eller anden årsag stopper. Distributed state store er et udtryk for al den information der skal til for at opretholde sværmens ønskede tilstand samt sværmens nuværende tilstand. Denne information deles konstant mellem alle managers, således at en hvilken som helst manager kan overtage lederrollen, hvis den node som er leder fejler.
Managers anvender “Raft Consensus Algorithm”, hvilket vil sige, at managers stemmer om hvor nye tasks skal køres. Man tolerer, at (N-1)/2 manager nodes fejler, og fejler flere end det, kan man ikke længere træffe scheduling beslutninger. Det vil sige, at har man 5 managers og 3 dør, kan der ikke schedules flere tasks før endnu en manager kommer op at køre igen. Ovenstående er vigtigt når man skal implementere sin swarm. Det har en betydning for, hvor fejltolerent systemet bliver. Vælger man et system med kun 1 manager, og den manager dør, kan systemet ikke længere igangsætte nye tasks. Det samme gælder ved 2 managers. Ved 3 kan systemet klare, at 1 manager fejler. Hvis vi følger matematikken med en tolerance på (N-1)/2, kan vi se, at det det næste lige tal ikke tillader at flere managers fejler. Se skema:
| Antal managers | Flertal | Fejltolerance |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
| 8 | 5 | 3 |
| 9 | 5 | 4 |
Derfor bør man altid stræbe efter et ulige antal managers, da dette giver den højest mulig fejltolerence, uden at tilføje en ekstra manager der alligevel ikke tilbyder højere fejltolerence.
Implementeringen
I vores projekt har jeg implementeret en Swarm på 5 hosts, hvoraf 3 er managers. Der er tale om én fysisk host og fire virtuelle maskiner, der kører på samme host. Det er naturligvis ikke ønskværdigt i et produktionsmiljø, da alle nodes vil fejle hvis hosten gør. Man ville fordele ens cluster over mange fysiske hosts i stedet. Sværmen er initeret med kommandoen docker swarm init. docker swarm join-token [OPTIONS] (worker|manager) returnerer et token man kan anvende til at join en swarm fra en anden node. Med docker node ls kan man få en oversigt over de nodes som indgår i sværmen:
1
2
3
4
5
6
7
leak@leakmonitor:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
fom7utv7k2kajfb0f8pd4dso2 * leakmonitor.vps.webdock.cloud Ready Active Reachable 24.0.7
kp9kr4hf42jpwrs2ej3df4q6w manager1 Ready Active Reachable 24.0.7
jh66mhp2dehd07k4ul51qhtek manager2 Ready Active Leader 24.0.7
phbsujbhhj45y988jmo6mvstj worker1 Ready Active 24.0.7
gftsam5dxhu2yop8f65v0em5c worker2 Ready Active 24.0.7
Ovenstående output viser de 5 hosts, hvor de tre øverste er managers. Sværmen er initeret på leakmonitor.vps… men da det er manager2 der står som leader, indikerer det, at leakmonitor.vps… af en eller anden grund har måtte videregive lederrollen. Et mere visuelt overblik over hvordan managers og workers arbejder kan ses nedenfor:
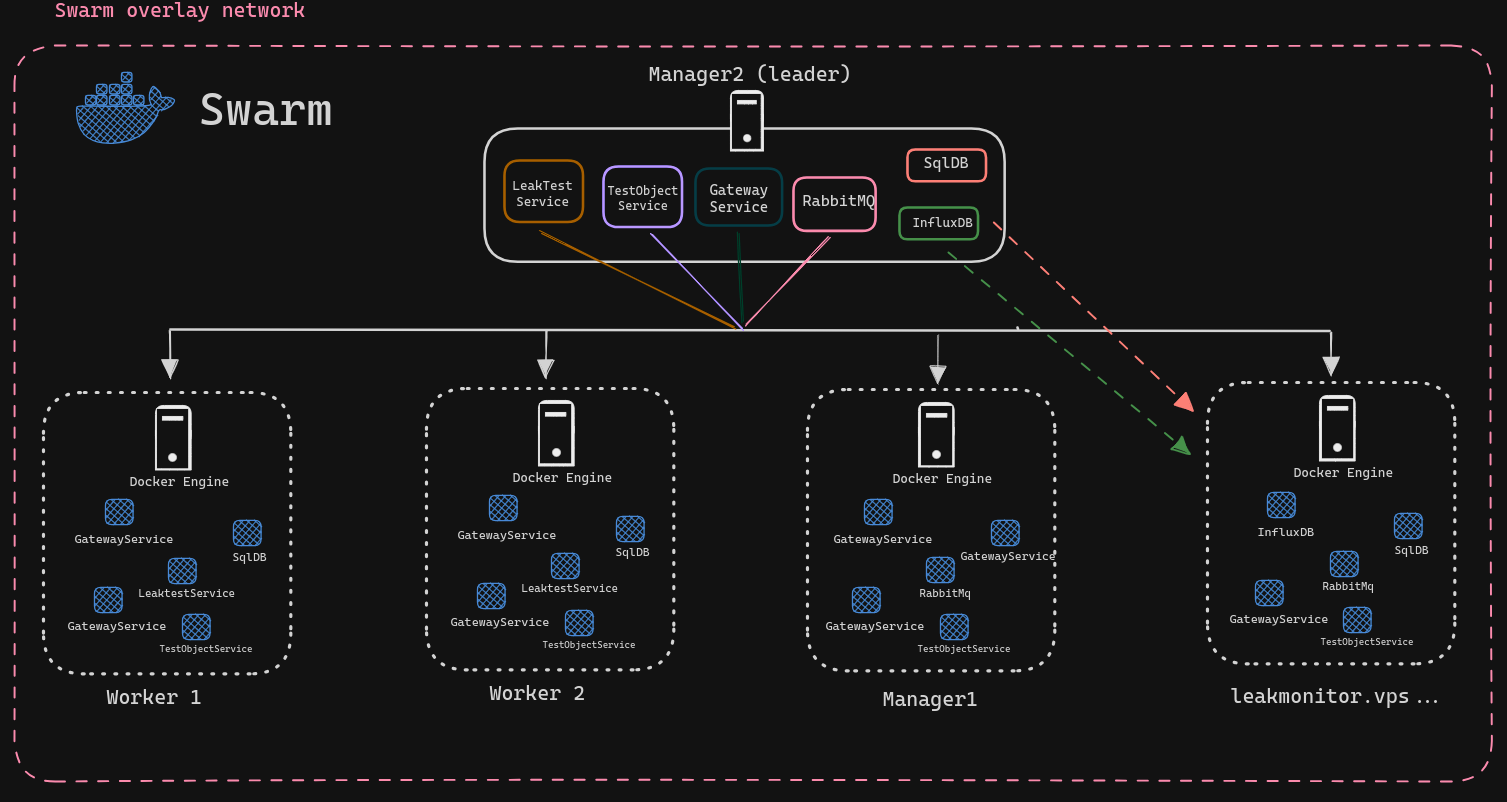
Lederen står altså for at fordele tasks (containers der kører de forskellige services) ud på de andre nodes. I dette eksempel, ligner det at manager2 ikke selv kører containers, men det gør den også. SqlDB og InfluxDB er underlagt den restriktion, at de skal køre på leakmonitor.vps… Det er de, da det er vigtigt, at stateful applikationer altid har adgang til deres data storage, som i Docker sættes for en container ved at forbinde en mappe inden i containers med en mappe på værten. Hvis man ikke gør det sådan, og den container som kører databasen går ned, vil man miste al data.